概率统计 施工中
MIT概率统计公开课学习笔记。
独立性
事件独立性向来是大众智商检验机,其中有不少乍看起来反常识的地方。
两事件A和B独立,等价于
. 两事件独立的根本含义是给定其中一方发生或不发生的信息,不能对我们推断另一事件起到任何帮助,只是我们定义事件独立时不写成 或者 (因为前者囊括了 的情况,这时 是无定义的)。 一个常见的误解就是混淆独立事件和不相容事件,如下图,事件A和B是不相容的,但不是相互独立的。因为给定了其中一方发生的前提,我们就可以断言另一方没有发生, 即一方提供的信息改变了我们对另一方的看法。假设A的概率是
,B的概率是 , . 
即使两事件A和B独立,在给定了一些信息的情况下也会改变我们对两事件发生的看法。由此引出了条件独立的概念:
。 这幅图比较形象,现给定前提A和B是独立的,但在C发生的条件下(在C发生的宇宙里),A和B之间就不再是独立的了,因为若 发生(AC阴影部分),我们可以断言 没有发生(BC阴影部分)。 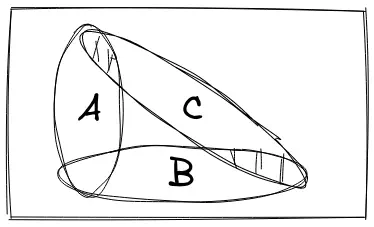
这告诉我们在常规概率模型中存在独立性并不意味着在条件概率模型中也具备独立性。教授又给了一个例子:假设有两枚不公平的硬币A和B,A正面向上的概率是0.9,B是0.1,等可能的概率选择一个硬币进行实验,考察如下几个问题:
如果明确正在使用的是硬币A,每次抛掷该硬币是独立的吗?显然是的,在确定了硬币的情况下,每次抛掷硬币正面向上的概率都和这个硬币的属性有关,不受前一次抛掷的影响。
在不知道抛掷的硬币是哪一个的情况下,第11次抛掷正面向上的概率是多少?
。 在已知前10次抛掷的结果都是正面向上的情况下,第11次抛掷正面向上的概率是多少?
前10次都是正面向上,给了我们很大的信心这个硬币是A(条件提供的信息改变了我们对假设的看法),在此情况下,可以推断第11次抛掷的结果会非常接近0.9(依然有很小的可能是B)。
。比较上一个问题,会发现“first 10 tosses are H”的信息改变了我们对假设的看法。
对于条件独立,即使事件A、B和C两两独立,也不能说明A、B和C三者相互独立(多个事件彼此相互独立是指其中一件事件的发生与否不会改变对剩下事件的看法)。教授也给出了一个非常直观的例子:
给定一个公平的硬币,抛一次正反两面的概率都是1/2,则抛两次的可能性如下表(将H指代正面向上):
HH HT TH TT 有:
- 事件A:第一次正面向上,
; - 事件B:第二次正面向上,
; - 事件C:两次抛掷是同样的面,
;
考察事件
,会发现A和B都发生给了我们一个非常明确的信息:两次抛掷的结果恰是HH,这进一步改变了我们对C发生的看法。已知是HH,则C已然发生,因此这个概率是1。 这时如果看一下 ,说明A、B和C是两两独立的。但 。 - 事件A:第一次正面向上,
一个经典问题:某人家有两个孩子,已知一个是男孩,问另一个是女孩的概率是多少?如果我没有学过条件概率一定会不假思索地回答1/2(教授称之为“naive answer”)。其实已有一个男孩的事实给了我们更多的信息,已经从样本空间排除掉了两个女孩的可能,因此正确答案是2/3。如果这个问题改变描述,某人家已经有一个男孩,问再生一个孩子是女孩的概率,那就是1/2了。
计数问题
理解排列和组合的关系
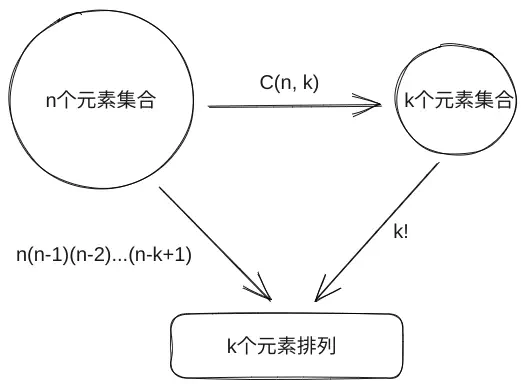
个不相同的物品乱序排列,可以看成有 个空位依次从物品中拿去放入,第一个空位有 个选择,第二个有 个选择……则可能的排列有 个。 如果物品一共有
个( ),类似的有 种顺序。 如果物品之间不计顺序,即从有n个元素的集合中选取k个,问子集的数量,记为
。应当注意到上面(2)的结果等价于先做这个步骤,再将k个物品全排列, 因此有 , 。
分割partition
样本空间有
个元素,不留空隙地划分为 块,假设每块的大小依次为 ,则第一块等价于我们从 中选出 个元素的集合,有 = 。以一个扑克牌的例子说明:将52张牌均分给4个人,问每个人分得一张方块的概率是多少?首先确定样本空间,是将牌分成4份的分法数量 , 其次将问题看成先分4张方块再分剩余48张牌的两个子问题,四张方块划分有 种分法,剩余48张牌我们要划分成4×12的四份,有 种分法,根据乘法法则最终结果为 。这个问题也可以用条件概率的视角看,画分支图,假设四张方块分别是ABCD,考虑事件“A和B在不同人的手里”、“A、B和C分在不同人的手里”和“A、B、C、D均在不同人的手里”。 组合其实是划分为两个部分
和 的分割问题。 INFO
当
很难计算,而 很容易时,很多全概率问题的关键都在于找到 中合适的分割来计算 。
离散型随机变量
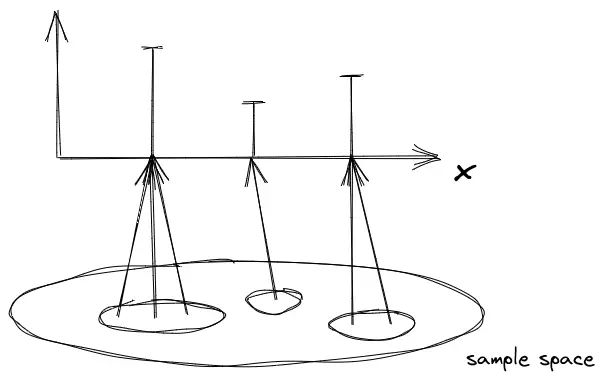
随机变量是样本空间到真实数值的一种映射,一种实值函数:
用
数学期望
常量的数学期望
; ; 。
复合型随机变量
设
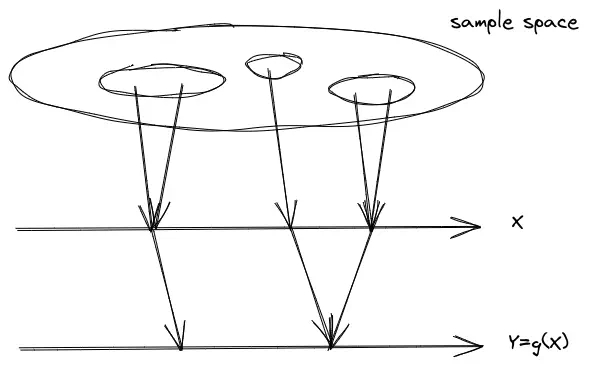
根据数学期望的定义,
由此公式可得
随机变量一个重要的特征量是方差:
方差的一些性质(
; ; 。
标准差:
几种常见的随机变量
伯努利随机变量
考虑一枚硬币,设正面向上的概率为
其数学期望为
二项随机变量
考虑
如果根据数学期望的定义求
利用数学期望的线性性质,注意到
注意
几何随机变量
在连续抛掷硬币的实验中,若考察第一次得到正面所需的次数
数学期望为
泊松随机变量
泊松随机变量可以看作是对二项随机变量的近似,更多讨论见后文的伯努利过程和泊松过程,这里简单给出推导:
考虑二项随机变量的分布列,其相应的参数为
当
指数随机变量
考虑几何随机变量的连续情形,即第一次得到正面所需的时间长度,将得到指数分布的概率密度:
其期望为
条件分布
根据分割样本空间的公式:
一个例子,抛掷公平硬币,正面向上的概率为
可解出
联合分布
联合分布
; (边缘分布列, 取遍 中所有不同的值); ; ; 。
应用示例
n个人将自己的帽子放在箱子里,每个人再依次从中不放回地取出一顶帽子,随机变量X表示刚好拿到自己帽子的人数,求X的期望和方差:
这个例子和二项分布有相似之处,但要注意到每次取帽子不再是独立的,前面取走了一顶帽子会影响后面的事件。
考虑随机变量
同样可以注意到
由于
由
依然注意有
有
独立性
(随机变量与事件的独立性)随机变量
独立于事件 是说 对一切 均成立。和条件概率类似(把 看成 ),有 。如果 ,也等价于说 对一切 成立,如果 前者无定义。 (随机变量与随机变量的独立性)随机变量之间的独立性和随机变量与事件之间的独立性基本一致。两个随机变量被称为相互独立的随机变量,要求它们满足
对一切 和 都成立。或者说 对一切 和满足 的 成立。 (条件独立)和条件概率类似,进一步可在给定事件
(要求 )的情况下定义两个随机变量的独立性。这时候所有事件的概率都需要换算成 的条件概率。例如我们称随机变量 和 在给定 的条件下是独立的,要求它们满足: 对一切 和 都成立。或者等价地说 对一切 和满足 的 都成立。
独立随机变量的期望和方差
若X和Y相互独立:
。证明: 。 。证明(利用随机变量平移方差不变,而期望的线性组合对随机变量没有独立性要求。令 , ,显然有 , ):
样本均值的期望和方差
假定任意地选取
假定
这也说明了为什么我们可以通过计算机模拟计算某事件的概率,例如前面的抛硬币,就是在用出现正面的次数比上
连续型随机变量
连续型随机变量通常用它的密度函数进行刻画,此时
类似地有
分布函数
我们分别用分布列和概率密度函数来刻画随机变量的取值规律,现在可以用一个统一的数学工具分布函数来刻画随机变量的取值规律。随机变量
正态分布
一个基础的连续型随机变量是正态分布。标准正态分布
对
如果直接对正态分布密度函数求积分是积不出来的,但一般的正态分布都可以转化(线性变换)为标准正态分布概率的计算,而标准正态分布我们有表格。如果
条件
在解释随机变量
下为教授评价重要性胜过本章任何内容的一图,图中右上为联合概率密度,中间的图像表示slice之后的一个切面为固定

随机变量的深入内容
随机变量函数的PDF
一个均匀分布的例子,
用更通用的两步走策略,首先将
单调函数
严格单调函数的一个重要性质是“可逆”,也就是说,存在函数
假设
卷积
设
协方差和相关性
两个随机变量
当
协方差的一些性质:
; ; 。
比较值得注意的是如下性质:如果随机变量
相关系数
和标准差类似,两个方差非0的随机变量
可以证明
随机变量和的方差
协方差使得我们可以计算多个随机变量(不要求独立)之和的方差。特别地,设随机变量
证明如下,简记
再论条件期望和方差
重期望定理
一个随机变量
既然
右边的两个式子前面已经很熟悉了,利用全期望定理,它们都等于
条件方差
首先,回忆:
因此类似地有:
由于
上面第二个等号应用了一次重期望定理。再由:
这里也应用了一次重期望定理。最后将两边相加可得:
这个公式说明样本总体的方差等于“average variability within sections + variability between sections“。
伯努利过程和泊松过程
伯努利过程
理解伯努利过程的“无记忆性”可以解决一些困难问题。已知伯努利过程首次成功时的试验总次数
如果将时间看成相互独立的连续小区间,称为“瞬间”,每个瞬间只包含一次独立的伯努利实验,每个区间只有两个状态:“成功”或“失败”。这和我们进行离散的若干次伯努利实验是一样的。举例来说,假定一个人每天都买一张彩票,单次中奖与否服从概率
一个想法是考虑区间
可行的方法是,观测到一个

第二个话题是第
即阶数为
第三个话题是伯努利过程的分裂和合并。假如每有一次成功时,我们以概率
泊松过程
时间是连续的,有时我们只有将时间段划分得足够小才能让它仅容纳下一次实验。但多少才算小?人们更喜欢考虑这个时间段的长度趋于零的情况,即连续型时间模型。我们不在每个小的时间区间(小到一个区间内只允许一次事件的发生与否)进行观察,而改为去记下每次事件发生的时间点,然后考察这些点落在一个大的时间范围里的概率,则落在不相交区间内的事件次数是独立的。令
对于足够小的时间间隔:
如果考察“区间
对比伯努利过程,这里的
令
第二个话题是泊松过程的合并和分裂,想象一个红灯和一个绿灯相互独立地闪烁,红灯的“arrive rate”是
第三个话题是随机插入的悖论。泊松过程的到达时间序列将时间轴分割成一串相邻的时间间隔序列,每个时间段开始于一个到达,结束于下一个到达。已经证得每个相邻时间段的长度(称为相邻到达时间)是独立的、参数为
这里的关键是,一个观测者到达的时刻更可能落在一个较大而不是较小(汽车在站台)的时间间隔区间里,因此,在这种情况下,观测者观测的平均长度将变长。类似的例子,假如公共汽车以等可能的概率以5分钟或10分钟到达,而我们“随机插入”,问从我们到站到下一班汽车到站的期望是多少?显然公共汽车的平均到达时间
这告诉我们确定“随机”的含义非常重要,假如要调查城市里公共汽车的拥挤情况,一种选择是随机抽取公共汽车进行调查,另一种选择是随机抽取乘客进行调查。显然后者的结果偏大,因为更有可能选中乘坐拥挤汽车的人。